Formatting and source coding – Wavecom W61PC V7.5.0 User Manual
Page 106
96
Fundamentals of Radio Data Transmission
WAVECOM Decoder W61PC/LAN Manual V7.5
Formatting and Source Coding
Formatting is the process whereby source data is prepared for the ensuing digital processing. Sometimes
this process is included in the functionality of source coding. The purpose of source coding is to reduce the
amount of redundant or unnecessary information from the raw data.
Bits are assembled into patterns or code words with a certain length which is expressed in number of
bits. The code words represent all or a part of the entire alphabet including letters, numbers, special char-
acters and control codes, or represent the pixels of a fax or samples of digitized speech.
Code words are assembled into alphabets or codes. In some codes the code words are of unequal
length. A distinction should be made between source coding, which is the coding used to communicate
between a data source or sink (a teleprinter, a PC) and data communication equipment, e.g. a modem or
a decoder, and channel coding, which is the coding used on the channel between the transmitting and
receiving data communication equipment. Sometimes the source code is also used as the channel code.
The Morse code is an unequal-length code. Code words are composed of dots - the smallest unit -,
dashes and spaces, one dash being equal to three dots. The character "E" is represented by the shortest
code word “dot” equal to one dot or '1' in binary notation. The character Zero (0) is represented by the
longest code word, "dash-dash-dash-dash-dash" equal to 19 dots or '1110111011101110111' in binary
notation. The reason for the unequal length of the code words was the desire to reduce the amount of
work for the operator when transmitting many messages. Samuel Morse found by visiting a Philadelphia
printing office, that the compositors had sorted the lead types in such a way that the types most frequent-
ly used were the ones most easily accessible.
An example of an equal-length, but non-integral code is the Baudot or ITA-2 alphabet, which was formerly
in use on the majority of the world's land lines and radio links. It is still the base for many codes con-
structed later, as compatibility to existing equipment and networks was essential.
In the ITA-2 code a character is represented by five bits. For instance, the letter "D" is represented by the
codeword '10110'. As we have five bits which can assume one of two possible states we are able to repre-
sent 25 = 32 characters. However, the number of all letters, figures, and special characters add up to
more than 32. Therefore a trick is employed: ITA-2 makes a distinction between two cases, lower (letters)
case and upper (figures) case. Shifting between these cases is accomplished by special shift characters. In
this manner it is possible to transfer (2 x 32) - 6 = 58 characters (the last six are subtracted because they
have same functions in either case). Shift characters are also used to toggle between Latin and non-Latin
alphabets in the same transmission, e.g. Latin-Cyrillic and Latin-Arab alphabets.
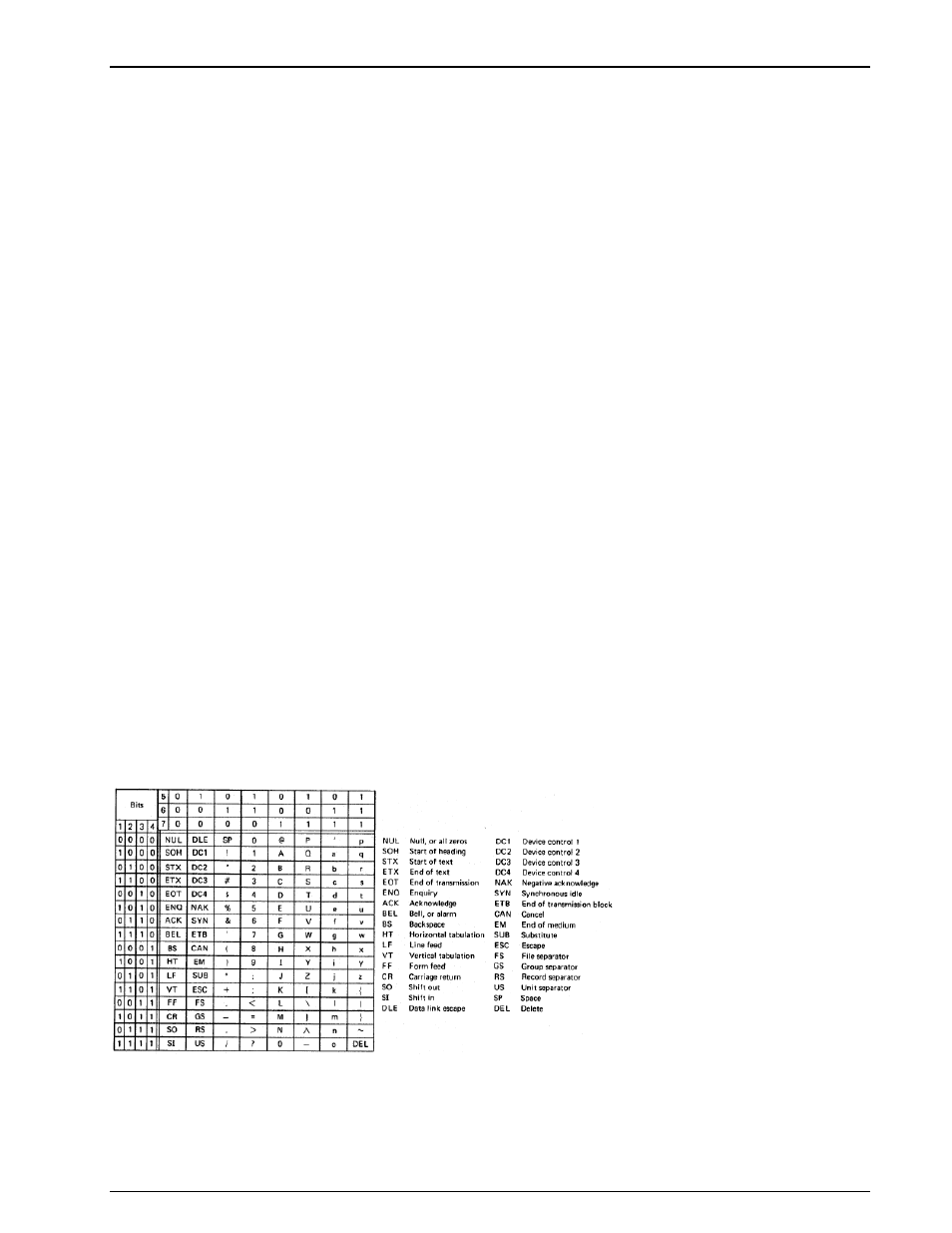
The alphabet most widely used in modern data communication is the ASCII code (American Standard
Code for Information Interchange) which is internationalized as ITU ITA-5. The alphabet is originally
based on 7-bit words, but normally 8 bits are used either to expand the alphabet or to include a parity bit.
Because of the number of bits available for each codeword, it is unnecessary to use special case shift
characters as for ITA-2. Also both capital and miniscule letters can be accommodated as well as non-
printing commands, and if 8-bit words are used completely transparent binary data.
7-bit ASCII code. Normally eight bits are transmitted with the 8th bit either set to 1 or 0, used for odd or
even parity or to expand the alphabet.